L'implementazione sarà fatta in Python ma, almeno nelle prime fasi, potrebbe anche essere sviluppata in Basic o Tcl. Via via che affronteremo le parti più complesse, faremo sempre più uso di strutture tipiche di Python, aumentando cosí la difficoltà dell'implementazione in Basic, mentre Tcl continuerà a rimanere una possibile opzione. La parte finale in stile OO sarà esclusivamente realizzata in Python.
Alcune funzioni che potrebbero essere implementate ma sono lasciate come esercizio al lettore sono:
import string
def n_parole(s):
lista = string.split(s)
return len(lista)
inp = open("menu.txt","r")
totale = 0
# accumula i totali parziali per ciascuna riga
for riga in inp.readlines():
totale = totale + n_parole(riga)
print "Il file contiene %d parole" % totale
inp.close()
Dobbiamo ora aggiungere il contatore delle righe e quello dei caratteri.
Il contatore delle righe è facile da aggiungere in quanto
il programma consiste di un ciclo sulle righe, quindi dobbiamo solo
aggiungere una variabile che viene incrementata ad ogni iterazione
del ciclo. Il conteggio dei caratteri è solo leggermente più
complesso, dato che possiamo effettuare un ciclo sulla lista delle parole,
sommando la lunghezza di ciascuna ad un'altra variabile.
Inoltre dobbiamo rendere il programma un po' più generale
facendogli leggere il nome del file dalla
linea di comando, oppure facendolo richiedere all'utente se non viene
specificato. Un modo alternativo di procedere potrebbe essere
quello di leggere i caratteri da stdin, come
fa il vero programma wc.
La versione finale del nostro wc quindi risulta:
import sys, string # Ricava il nome del file dalla linea di comando, o chiede all'utente if len(sys.argv) != 2: nome = raw_input("Nome file: ") else: nome = sys.argv[1] inp = open(nome,"r") # Inizializza i contatori; le variabili vengono create parole = 0 righe = 0 caratt = 0 for riga in inp.readlines(): righe = righe + 1 # Suddivide la riga in parole e le conta lista = string.split(riga) parole = parole + len(lista) caratt = caratt + len(riga) # Determina la lunghezza della riga, che include gli spazi, ecc. print "%s contiene %d righe, %d parole e %d caratteri" % (nome, righe, parole, caratt) inp.close()
Se conoscete il comando wc di Unix, saprete che specificando più nomi di files mediante un carattere jolly si ottengono i conteggi per ciascun file ed i totali generali. Questo programma tratta invece solo semplici nomi di files. Se volete estenderlo in modo che possa trattare anche più file per mezzo di caratteri jolly leggete la documentazione del modulo glob, che consente di creare una lista di nomi di file sulla quale potetre costruire un ciclo di iterazione. Avrete bisogno di un gruppo di contatori per ciascun file e dei contatori per i totali generali. Oppure potete utilizzare una struttura dictionary.
Approfondendo un po' l'analisi risulta evidente che è sufficiente raccogliere le parole ed i segni di punteggiatura e poi analizzare questi ultimi per contare proposizioni, frasi, ecc. (avendo definito quali entità sono considerate proposizioni e quali frasi, dipendentemente dai relativi segni di punteggiatura). In questo modo occorre solo una iterazione sull'intero file, seguita da una iterazione sulla lista dei segni di interpuzione, che risulta assai più breve. Per illustrare il procedimendo utilizziamo uno pseudo-codice:
per ogni riga nel file:
incrementa contatore righe
se la riga è vuota:
incrementa contatore capoversi
suddividi riga in gruppi di caratteri
per ogni gruppo di caratteri:
incrementa contatore gruppo
trasferisci i caratteri di punteggiatura in un dizionario
se riga terminata:
cancella il gruppo
altrimenti:
incrementa contatore parole
contatore frasi = somma di('.','?','!')
contatore proposizioni = somma di tutti i caratteri di punteggiatura (non è granché come definizione ...)
scrivi numero di paragrafi, righe, frasi, proposizioni, gruppi di caratteri, parole.
per ogni carattere di punteggiatura:
scrivi contatore
Sembra quindi che possiamo creare, diciamo, quattro funzioni usando
i raggruppamenti naturali visti sopra. Questo può risultare utile
nel creare un modulo che possa essere riusato, completamente o almeno in parte.
############################# # Modulo: grammatica # Creazione: A.J. Gauld, 2000,8,12 # # Scopo: # Conta capoversi, righe, frasi, proposizioni, gruppi di caratteri # parole e segni di punteggiatura in un file di testo. Si assume # che le frasi terminino con [.!?] e che i capoversi siano separati # da una riga bianca. Una proposizione è semplicemente una parte # di frase terminata da un segno di punteggiatura (semplicistico, ma # magari in futuro faremo qualche cosa di meglio!). # # Uso: Nell'uso piu' semplice accetta un nome di file come argomento # e scrive tutti i dati statistici. Piu' in generale le funzioni # possono essere utilizzate da un altro modulo per realizzare # operazioni piu' utili. ############################# import string, sys ############################ # inizializza le variabili globali num_capo = 1 num_righe, num_frasi, num_propos, num_parole = 0,0,0,0 gruppi = [] num_puntegg = {} alnum = string.letters + string.digits finali = ['.','?','!'] puntegg = ['&','(',')','-',';',':',','] + finali for c in puntegg: num_puntegg[c] = 0 format = """%s contiene: %d capoversi, %d righe and %d frasi. Queste a loro volta contengono %d proposizioni ed un totale di %d parole.""" ############################ # Definisci le funzioni che fanno il lavoro def estraiGruppiCaratteri(filein): pass def estraiPunteggiatura(listaParole): pass def scriviValori(): print format % (sys.argv[1],num_capo, num_righe, num_frasi, num_propos, num_parole) def Analizza(filein): estraiGruppiCaratteri(filein) estraiPunteggiatura(gruppi) scriviValori() # Fai in modo che il programma venga lanciato correttamente dalla linea # di comando (nel qual caso la variabile "magica" __name__ contiene # la stringa "__main__" if __name__ == "__main__": if len(sys.argv) != 2: print "Uso: python grammatica.py <nome file>" sys.exit() else: Documento = open(sys.argv[1],"r") Analizza(Documento)Invece che riportare tutto il programma in un unico lungo listato discuteremo prima la struttura vista fin qui e poi analizzeremo ciascuna delle tre funzioni principali. Per ottenere un programma funzionante dovrete riunire insieme tutte le varie parti.
Per prima cosa notate il commento iniziale. Si tratta di una pratica comune che consente a chi legge il codice di farsi un'idea del contenuto e del suo uso. Anche l'informazione relativa alla versione (autore e data) può essere utile per confrontare i risultati con altri che potrebbero utilizzare una diversa versione, precedente o successiva.
La parte finale rappresenta una caratteristica speicifica di Python che ad ogni modulo lanciato dalla linea di comando assegna il nome __main__. Il programma verifica il contenuto della speciale variabile built-in __name__ e stabilisce che modulo non è stato semplicemente importato ma deve essere eseguito e quindi passa ad eseguire l'istruzione necessaria all'interno della frase if.
Tale istruzione contiene un suggerimento per l'utente che specifica il modo d'uso e che appare se il programma viene lanciato senza specificare un nome di file, o se ne vengono specificati troppi.
Notate infine che la funzione Analizza() ha il solo scopo di chiamare le altre funzioni nell'ordine previsto. Anche questa è una pratica comune che consente all'utente di sfruttare tutta la funzionalità in modo semplice chiamando Analizza(), oppure di chiamare direttamente le funzioni primitive di livello inferiore.
per ogni riga in file:
incrementa contatore riga
se la riga è vuota:
incrementa contatore capoverso
suddividi riga in gruppi di caratteri
Possiamo realizzare questa funzione in Python in modo davvero facile:
# Usa variabili globali per i contatori e la lista dei gruppi di caratteri def estraiGruppiCaratteri(filein): global num_capo, num_righe, gruppi try: for riga in filein.readlines(): num_righe = num_righe + 1 if len(riga) == 1: # fine paragrafo solo a fine riga num_capo = num_capo + 1 else: gruppi = gruppi + string.split(riga) except: print "Errore di lettura file ", sys.argv[1] sys.exit()Nota 1: Abbiamo usato la parola chiave global per dichiarare le variabili che vengono create al di fuori della funzione. Se non lo avessimo fatto, Python avrebbe creato nuove variabili con lo stesso nome locali rispetto a questa funzione. Cambiare il valore di queste variabili non avrebbe alcun effetto sui valori al livello del modulo (cioè globali).
Nota 2: Abbiamo usato un costrutto try/except per intercettare qualunque errore, segnalare il problema ed uscire.
Per questa funzione occorre un po' più di sforzo e l'impiego di un paio di nuove caratteristiche di Python.
Lo pseudo codice risulta come segue:
per ogni gruppo di caratteri:
incrementa contatore gruppo
trasferisci i caratteri di punteggiatura in un dictionary
se fine caratteri:
cancella gruppo
altrimenti: incrementa contatore parole
Ecco una prima versione:
def estraiPunteggiatura(listaParole):
global num_puntegg
for elem in listaParole:
while elem and (elem[-1] not in alnum):
p = elem[-1]
elem = elem[:-1]
if p in num_puntegg.keys():
num_puntegg[p] = num_puntegg[p] + 1
else: num_puntegg[p] = 1
Noterete che qui manca l'ultima istruzione if/else
del corrispondente pseudo codice. È stata tralasciata per
semplicità e perché si suppone che in pratica troveremo
solo pochi casi di parole composte esclusivamente da segni di punteggiatura.
Comunque la aggiungeremo nella versione finale del codice.
Nota 1: listaParole viene passata come argomento in modo che gli utilizzatori potranno passare la loro lista invece che essere costretti ad usare un file in ogni caso.
Nota 2: Abbiamo assegnato elem[:-1] ad elem. Questa operazione in Python è chiamata slicing [affettamento, N.d.T.] ed il carattere ":" indica semplicemente di trattare l'indice come un range. Ad esempio potremmo specificare elem[3:6] per estrarre dalla lista elem[3], elem[4] ed elem[5] e metterli in un'altra.
L'estremo omesso rappresenta l'inizio o la fine della lista a seconda di quale lato del carattere ":" è mancante. Quindi elem[3:] avrebbe indicato tutti i membri di elem da elem[3] alla fine. Anche questa è una caratteristica assai utile di Python. La lista elem originale viene persa (ed il relativo spazio opportunamente recuparato dal garbage collector) e la nuova lista creata viene assegnata ad elem.
Nota 3: Abbiamo usato un indice negativo per eliminare l'ultimo carattere da elem. Ecco un'altra utile caratteristica di Python. Inoltre abbiamo usato un ciclo per considerare il caso in cui un gruppo termini con più di un carattere di punteggiatura.
Quando poi la funzione è stata provata è risultato chiaro che occorre fare la stessa operazione anche all'inizio della stringa, altrimenti il programma funziona correttamente con le parentesi chiuse, ma non con le parentesi aperte. Per risolvere il problema scriveremo una nuova funzione rifila che rimuove i segni di punteggiatura in testa ed in coda ad un gruppo di caratteri:
#########################################################
# Nota: rifila usa un metodo ricorsivo in cui la condizione di
# terminazione e' 0 oppure -1. Qualunque valore diverso da
# -1, 0 o 2 genera un errore "FineNonValida"
##########################################################
def rifila(elem,fine = 2):
""" elimina caratteri non alfanumerici dai lati sinistro(0), destro(-1) o entrambi(2)"""
if fine not in [0,-1,2]:
raise "FineNonValida"
if fine == 2:
rifila(elem, 0)
rifila(elem, -1)
else:
while (len(elem) > 0) and (elem[fine] not in alnum):
car = elem[fine]
if car in num_puntegg.keys():
num_puntegg[car] = num_puntegg[car] + 1
if fine == 0: elem = elem[1:]
if fine == -1: elem = elem[:-1]
Notate come l'uso della ricorsione, combinato con un parametro che ha
un valore di default ci consente di definire una sola funzione rifila
che aggiusta entrambe le estremità della stringa, ma
che può essere utilizzata per operare su uno solo dei lati
fornendo un valore all'argomento fine. I valori di fine sono scelti in modo
da riflettere il modo di indirizzamento di Python: 0 per l'estremità
sinistra e -1 per quella destra. Inizialmente avevamo scritto due diverse
funzioni, una per ciascuna estremità ma la loro similarità
ha suggerito che potevamo combinarle usando un parametro.
A questo punto estraiPunteggiatura diventa quasi banale:
def estraiPunteggiatura(listaParole):
for elem in listaParole:
rifila(elem)
# Si cancellano tutte le "parole" vuote
for i in range(len(listaParole)):
if len(listaParole[i]) == 0:
del(listaParole[i])
Nota 1: Adesso abbiamo incluso la cancellazione delle parole vuote.
Nota 2: Per migliorare la riusabilità sarebbe stato meglio dividere rifila in parti ancora più piccole. Cioè avremmo potuto creare una funzione per eliminare un carattere da una o l'altra estremità della stringa, in grado di riportare come valore il carattere eliminato. Poi una seconda funzione avrebbe potuto chiamare la prima ripetutamente per ottenere il risultato desiderato. Tuttavia, dato che il nostro programma ha lo scopo di produrre statistiche su un testo e non quello più generico di elaborare un testo, avremmo dovuto propriamente creare un modulo separato da importare. Ma siccome questo sarebbe stato usato per un solo scopo, tutto ciò non sarebbe poi stato molto utile. Quindi lo lasceremo in questa forma.
L'unica cosa che resta da fare è migliorare l'aspetto della visualizzazione dei risultati, in modo da includere la punteggiatura ed i conteggi. Sostituiamo quindi la funzione scriviValori vista sopra con la seguente:
def scriviValori():
global num_frasi, num_propos
for p in finali:
num_frasi = num_frasi + num_puntegg[p]
for c in num_puntegg.keys():
num_propos = num_propos + num_puntegg[c]
print format % (sys.argv[1],
num_capo, num_righe, num_frasi,
num_propos, len(gruppi))
print "Sono stati usati i seguenti segni di punteggiatura:"
for p in num_puntegg.keys():
print "\t%s\t:\t%3d" % (p, num_puntegg[p])
Se avete riunito correttamente tutte le funzioni descritte,
adesso dovreste essere in grado di scrivere:
C:> python grammatica.py testo.txtper ottenere i dati statistici relativi al vostro file testo.txt (o comunque vogliate chiamarlo). Possiamo discutere di quanto tutto ciò sia effettivamente utile, ma spero che seguendo lo sviluppo del codice abbiate potuto farvi un'idea di come potete scrivere programmi vostri. La cosa importante è provare. Non dovete vergognarvi se vi trovate a seguire più strade diverse prima di scegliere quella giusta, spesso nel ripetere i tentativi si apprendono utili nozioni.
Per concludere il nostro corso riscriveremo il modulo grammatica in modo da usare tecniche OO. Nel farlo scoprirete che l'approccio OO porta a scrivere moduli che risultano ancora più flessibili ed estensibili.
Uno dei problemi principali per l'utilizzatore dei nostri moduli è rappresentato dal fatto che essi si basano sull'uso di variabili globali. Questo significa che il modulo può analizzare solo un documento alla volta; ogni tentativo di analizzarne più di uno causerebbe la sovrascrittura delle variabili globali.
Se spostiamo le variabili globali all'interno di una classe, allora possiamo creare varie istanze della classe (una per file) e ciascuna istanza dispone del proprio insieme di variabili. Inoltre, se progettiamo i moduli in modo sufficientemente granulare, possiamo realizzare un'architettura all'interno della quale è facile, per chi crea un nuovo tipo di documento, modificare i criteri di ricerca in modo da poter trattare le regole del nuovo tipo (ad esempio per eliminare dalla lista delle parole tutti i comandi HTML dovendo trattare un documento in questo formato).
vediamo una prima stesura:
#! /usr/local/bin/python ################################ # Modulo: documento.py # Autore: A.J. Gauld # Data: 2000/08/12 # Versione: 2.0 ################################ # Questo modulo definisce una classe Documento che # puo essere specializzata in sottoclassi per diverse # categorie di documenti (testo, HTML, LaTeX, ecc.) # A scopo di esempio si forniscono le sottoclassi # per i tipi testo e HTML. # # I servizi principali includono: # - estraiGruppiCaratteri(), # - estraiParole(), # - scriviValori(). ################################ import sys,string class Documento: def __init__(self, nomefile): self.nomefile = nomefile self.num_capo = 1 self.num_righe, self.num_frasi, self.num_propos, self.num_parole = 0,0,0,0 self.alnum = string.letters + string.digits self.finali = ['.','?','!'] self.c_puntegg = ['&','(',')','-',';',':',','] + self.finali self.righe = [] self.gruppi = [] self.num_puntegg = {} for c in self.c_puntegg + self.finali: self.num_puntegg[c] = 0 self.format = """%s contiene: %d capoversi, %d righe e %d frasi. Queste a loro volta contengono %d proposizioni ed un totale di %d parole""" def leggiRighe(self): try: self.filein = open(self.nomefile,"r") self.righe = self.filein.readlines() except: print "Errore di lettura file ",self.nomefile sys.exit() def estraiGruppiCaratteri(self, righe): for riga in righe: riga = riga[:-1] # cancella il '\n' a fine riga self.num_righe = self.num_righe + 1 if len(riga) == 0: # riga vuota => fine capoverso self.num_capo = self.num_capo + 1 else: self.gruppi = self.gruppi + string.split(riga) def estraiParole(self): pass def scriviValori(self, parag=1, righe=1, frasi=1, parole=1, punt=1): pass def Analizza(self): self.leggiRighe() self.estraiGruppiCaratteri(self.righe) self.estraiParole() self.scriviValori() class DocumentoTesto(Documento): pass class DocumentoHTML(Documento): pass if __name__ == "__main__": if len(sys.argv) != 2: print "Uso: python documento.py <nomefile>" sys.exit() else: D = Documento(sys.argv[1]) D.Analizza()
Per scrivere il codice della classe definiamo adesso il metodo estraiParole. Potremmo semplicemente copiare quello già fatto nella versione precedente e creare il metodo rifila però, dato che vogliamo rendere la versione OO facilmente estensibile, suddivideremo estraiParole in una successione di passi. In modo che poi nelle sottoclassi dovremo solo effettuare l'override dei passi elementari e non dell'intero metodo estraiParole. Questo dovrebbe consentire un campo di applicabilità assai più ampio ed in grado di trattare diversi tipi di documento.
In particolare aggiungeremo metodi per eliminare gruppi di caratteri non validi e per eliminare caratteri non voluti all'inizio ed alla fine della stringa. Aggiungiamo quindi a Documento tre metodi e realizziamo estraiParole utilizzando i metodi definiti.
class Documento:
# .... come sopra
def estraiParole(self):
for w in self.gruppi:
self.lrifila(w)
self.rrifila(w)
self.eliminaEccezioni()
def eliminaEccezioni(self):
pass
def lrifila(self,parola):
pass
def rrifila(self,parola):
pass
Notate che abbiamo usato nel corpo dei metodi la semplice istruzione pass, che non fa assolutamente niente. In seguito definiremo come i metodi devono operare per ciascun tipo di documento effettivo.
Un documento di testo si presenta cosí:
class DocumentoTesto(Documento):
def lrifila(self,parola):
while (len(parola) > 0) and (parola[0] not in self.alnum):
car = parola[0]
if car in self.num_puntegg.keys():
self.num_puntegg[car] = self.num_puntegg[car] + 1
parola = parola[1:]
return parola
def rrifila(self,parola):
while (len(parola) > 0) and (parola[-1] not in self.alnum):
car = parola[-1]
if car in self.num_puntegg.keys():
self.num_puntegg[car] = self.num_puntegg[car] + 1
parola = parola[:-1]
return parola
def eliminaEccezioni(self):
ultimo = len(self.gruppi)
n = 0
while n < ultimo:
if (len(self.gruppi[n]) == 0):
del(self.gruppi[n])
ultimo = ultimo - 1
n = n+1
Le funzioni rifila sono sostanzialmente identiche a quella del modulo
grammatica.py divisa in due parti. Abbiamo definito
la funzione eliminaEccezioni per rimuovere le parole vuote.
Notate anche che la struttura di quest'ultimo metodo è stata modificata per usare un ciclo while al posto del for usato precedentemente. Questo perché durante le prove è stato scoperto un errore; infatti, pur cancellando elementi dalla lista, il valore del range calcolato all'inizio si manteneva uguale e ciò risultava nel tentativo di accedere ad elementi della lista non esistenti. Per evitare il problema abbiamo usato il ciclo while ed abbiamo aggiunto il ricalcolo dell'indice dell'ultimo elemento ogni volta che un elemento viene rimosso.
DocumentoHTML diviene allora:
class DocumentoHTML(DocumentoTesto):
def eliminaEccezioni(self):
""" usa le espressioni regolari per eliminare tutti i: <.+?> """
import re
campione = re.compile("<.+?>")# usa esp.reg. non "greedy" [Per il significato del termine "greedy" si rimanda al manuale di Python, N.d.t.]
R = 0
while R < len(self.righe):
if len(self.righe[R]) > 1: # se non e' vuota
self.righe[R] = campione.sub('', self.righe[R])
if len(self.righe[R]) == 1:
del(self.righe[R])
else: R = R+1
else: R = R+1
def estraiParole(self):
self.eliminaEccezioni()
for i in range(len(self.gruppi)):
w = self.gruppi[i]
w = self.lrifila(w)
self.gruppi[i] = self.rrifila(w)
DocumentoTesto.eliminaEccezioni(self) # elimina parole vuote
Nota 1: L'unica cosa da sottolineare è la chiamata a
self.eliminaEccezioni prima di rifila e poi a
DocumentoTesto.eliminaEccezioni. Se avessimo usato
il metodo ereditato estraiParole, questo avrebbe chiamato
il nostro eliminaEccezioni dopo rifila, cosa che non vogliamo.
Infine dobbiamo modificare Analizza in modo da chiamare calcolaStat() e la funzione main in modo da chiamare visualizzaStat() dopo Analizza. Con questi cambiamenti il codice continuerà a funzionare come prima, almeno per quanto riguarda l'uso da linea di comando.
Il codice cosí modificato diviene:
def calcolaStat(self):
self.num_parole = len(self.gruppi)
for c in self.finali:
self.num_frasi = self.num_frasi + self.num_puntegg[c]
for c in self.num_puntegg.keys():
self.num_propos = self.num_propos + self.num_puntegg[c]
def visualizzaStat(self):
print self.format % (self.nomefile, self.num_capo,
self.num_righe, self.num_frasi,
self.num_propos, self.num_parole)
print "Sono stati usati i seguenti segni di punteggiatura:"
for i in self.num_puntegg.keys():
print "\t%s\t:\t%4d" % (i,self.num_puntegg[i])
e poi:
if __name__ == "__main__":
if len(sys.argv) != 2:
print "Uso: python documento.py <nomefile>"
sys.exit()
else:
try:
D = DocumentoHTML(sys.argv[1])
D.Analizza()
D.visualizzaStat()
except:
print "errore nell'analisi del file: %s" % sys.argv[1]
E adesso siamo pronti a creare un involucro grafico attorno alla nostra classe Documento.
Il primo passo consiste nel cercare di visualizzare l'aspetto che desideriamo ottenere. Poiché vogliamo che l'utilizzatore possa specificare un nome di file la GUI dovrà avere un elemento di controllo di tipo Edit oppure Entry. Inoltre l'utente dovrà specificare se vuole analizzare file di testo o HTML e questo tipo di scelta "uno di molti" viene di solito implementata mediante un gruppo di elementi di controllo Radiobutton. Questi elementi di controllo saranno raggruppati insieme per far capire che sono in relazione fra loro.
Il successivo elemento della GUI è rappresentato da un widget in grado di visualizzare il risultato. Potremmo utilizzare molti elementi di tipo Label, uno per ogni contatore. Utilizzeremo invece un semplice elemento Text nel quale possiamo scrivere stringhe; questo sembra più vicino allo spirito del modo di visualizzazione della versione da linea di comando, anche se in definitiva si tratta di una scelta che dipende dalle preferenze del programmatore.
Infine occorre un modo per iniziare l'analisi e per terminare l'applicazione. Poiché si utilizza un widget text per visualizzare i risultati, potrebbe essere utile un ulteriore elemento di controllo per cancellare l'area di testo. Questi comandi sono facilmente realizzabili con elementi di tipo Button.
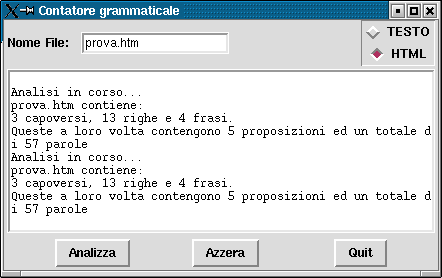
Rappresentando queste idee in modo grafico otteniamo qualche cosa come:
+-------------------------+-----------+ | NOME FILE | O TESTO | | | O HTML | +-------------------------+-----------+ | | | | | | | | | | +-------------------------------------+ | | | ANALIZZA AZZERA ESCI | | | +-------------------------------------+
from Tkinter import * import documento ################### DEFINIZIONE DELLE CLASSI ###################### class AppGrammatica(Frame): def __init__(self, padre=0): Frame.__init__(self,padre) self.tipo = 2 # crea la variabile con un valore predefinito self.master.title('Contatore grammaticale') self.creaInterf()
Abbiamo importato i moduli Tkinter e documento. Per quanto riguarda il primo abbiamo reso visibili tutti i nomi nel modulo corrente, mentre per i nomi dell'altro dovremo usare il prefisso "documento".
Abbiamo anche definito un metodo __init__ che chiama il metodo Frame.__init__ della superclasse, per fare in modo che Tkinter sia correttamente inizializzato. Quindi creiamo un attributo per memorizzare il valore del tipo di documento ed infine chiamiamo il metodo creaInterf che a sua volta crea tutti i widget necessari.
def creaInterf(self):
# Informazioni sul file: name e tipo
fFile = Frame(self)
Label(fFile, text="Nome File: ").pack(side="left")
self.eName = Entry(fFile)
self.eName.insert(INSERT,"prova.htm")
self.eName.pack(side="left", padx=5)
# Abbiamo bisogno di un altro frame per allineare
# i radiobutton con il nome file
fTipo = Frame(fFile, borderwidth=1, relief=SUNKEN)
self.rTesto = Radiobutton(fTipo, text="TESTO",
variable = self.tipo, value=2,
command=self.faiTesto)
self.rTesto.pack(side=TOP)
self.rHTML = Radiobutton(fTipo, text="HTML",
variable=self.tipo, value=1,
command=self.faiHTML)
self.rHTML.pack(side=TOP)
# la selezione di default e' "testo"
self.rTesto.select()
fTipo.pack(side="right", padx=3)
fFile.pack(side="top", fill=X)
# L'area di testo riceve l'uscita, contorniamola con un bordo
self.areaTesto = Text(fApp, width=60, height=12)
self.areaTesto.pack(side=TOP, padx=3, pady=3)
# per finire aggiungi alcuni bottoni per fare il lavoro
fBott = Frame(self)
self.bAnal = Button(fBott, text="Analizza",
command=self.faiAnalizza)
self.bAnal.pack(side=LEFT, anchor=W, padx=50, pady=2)
self.bAzzera = Button(fBott, text="Azzera",
command=self.faiAzzera)
self.bAzzera.pack(side=LEFT, padx=10)
self.bEsci = Button(fBott, text="Quit",
command=self.faiEsci)
self.bEsci.pack(side=RIGHT, anchor=E, padx=50, pady=2)
fBott.pack(side=BOTTOM, fill=X)
self.pack()
Invece che spiegare ogni singolo passo, vi invito a consultare la guida introduttiva a Tkinter che potete trovare sul sito web di Python. Si tratta di un'ottima introduzione e, contemporaneamente, di un manuale di riferimento per Tkinter. Il principio generale consiste nel creare i widget dalle classi corrispondenti, specificando le opzioni mediante argomenti con nome e poi il widget viene posizionato con pack all'interno del relativo frame.
Gli altri punti da notare sono l'uso di Frame ausiliari per contenere i Radiobutton ed i Button per comandi. I Radiobutton utilizzano anche un paio di opzioni di nome variable e value, il primo associa i Radiobutton specificando una variabile esterna comune (self.tipo) e l'altro assegna un valore diverso a ciascun Radiobutton. Notate anche l'opzione command=xxx passata agli elementi Button. Servono per definire i metodi che devono essere chiamati da Tkinter quando il bottone viene "premuto". Il codice dei metodi è il seguente:
############## METODI PER LA GESTIONE DEGLI EVENTI ################ # E' arrivato il momento di uscire... def faiEsci(self): import sys sys.exit() # azzera l'area di testo def faiAzzera(self): self.areaTesto.delete(1.0, END) self.rTesto.select() # Assegna il valore ai radiobutton def faiTesto(self): self.tipo = 2 def faiHTML(self): self.tipo = 1
Questi metodi sono tutti abbastanza semplici e spero che a questo punto siano chiaramente comprensibili. L'ultimo dei metodi per la gestione degli eventi è quello che attiva l'analisi:
# Crea il tipo di documento appropriato ed analizzalo.
# Poi visualizza i risultati
def faiAnalizza(self):
nomefile = self.eName.get()
if nomefile == "":
self.areaTesto.insert(END,"\nNome file non specificato!\n")
return
if self.tipo == 2:
doc = documento.DocumentoTesto(nomefile)
else:
doc = documento.DocumentoHTML(nomefile)
self.areaTesto.insert(END, "\nAnalisi in corso...\n")
doc.Analizza()
str = doc.format % (nomefile,
doc.num_capo, doc.num_righe,
doc.num_frasi, doc.num_propos, doc.num_parole)
self.areaTesto.insert(END, str)
Anche in questo caso dovreste essere in grado di leggere il codice e capirne il funzionamento. I punti chiave sono:
Tutto ciò che resta da fare è creare un'istanza
dell'oggetto Applicazione e attivare il loop degli eventi, come
di seguito:
miaApp = AppGrammatica() miaApp.mainloop()
Vediamo come appare il risultato finale in ambiente Linux, mostrando il risultato dell'analisi di un file HTML, prima in modo Testo e poi in modo HTML:
Ed è tutto. Potete proseguire rendendo l'analisi del tipo HTML più sofisticata, se volete. Oppure potete creare nuovi moduli per trattare altri tipi di documento. Potete anche provare a sostituire l'area di testo con un lista di Label racchiusi dentro un Frame. Ma per quanto ci riguarda concludiamo qui. Nel prossimo capitolo riportiamo alcune idee su come potete proseguire, seguendo le vostre aspirazioni nel campo della programmazione. L'importante è divertirsi e ricordare sempre che il computer è stupido!
Se avete domande o suggerimenti relativi a questa pagina
mandate un e-mail all'autore:
alan.gauld@yahoo.co.uk
o al traduttore italiano:
lfini@arcetri.astro.it