It will be a Python implementation but at least the initial stages could be written in BASIC or Tcl instead. As we move to the more complex parts we will make increasing use of Python's built in data structures and therefore the difficulty in using BASIC will increase, although Tcl will still be an option. Finally the OO aspects will only apply to Python.
Additional features that could be implemented but will be left as excercises for the reader are:
(Average words per sentence) + (Percentage of words more than 5 letters) * 0.4and indicates the complexity of the text,
import string
def numwords(s):
list = string.split(s)
return len(list)
inp = open("menu.txt","r")
total = 0
# accumulate totals for each line
for line in inp.readlines():
total = total + numwords(line)
print "File had %d words" % total
inp.close()
We need to add a line and character count. The line count is easy since
we loop over each line we just need a variable to increment on each iteration
of the loop. The character count is only marginally harder since we can
iterate over the list of words adding their lengths in yet another variable.
We also need to make the program more general purpose by reading the name of the file from the command line or if not provided, prompting the user for the name. (An alternative strategy would be to read from standard input, which is what the real wc does.)
So the final wc looks like:
import sys, string # Get the file name either from the commandline or the user if len(sys.argv) != 2: name = raw_input("Enter the file name: ") else: name = sys.argv[1] inp = open(name,"r") # initialise counters to zero; which also creates variables words = 0 lines = 0 chars = 0 for line in inp.readlines(): lines = lines + 1 # Break into a list of words and count them list = string.split(line) words = words + len(list) chars = chars + len(line) # Use original line which includes spaces etc. print "%s has %d lines, %d words and %d characters" % (name, lines, words, chars) inp.close()
If you are familiar with the Unix wc command you know that you can pass it a wild-carded filename to get stats for all matching files as well as a grand total. This program only caters for straight filenames. If you want to extend it to cater for wild cards take a look at the glob module and build a list of names then simply iterate over the file list. You'll need temporary counters for each file then cumulative counters for the grand totals. Or you could use a dictionary instead...
Thinking about it a little further it becomes evident that if we simply collect the words and punctuation characters we can analyse the latter to count sentences, clauses etc. (by defining what we consider a sentence/clause in terms of punctuation items). This means we only need to interate over the file once and then iterate over the punctuation - a much smaller list. Let's try sketching that in pseudo-code:
foreach line in file:
increment line count
if line empty:
increment paragraph count
split line into character groups
foreach character group:
increment group count
extract punctuation chars into a dictionary - {char:count}
if no chars left:
delete group
else: increment word count
sentence count = sum of('.', '?', '!')
clause count = sum of all punctuation (very poor definition...)
report paras, lines, sentences, clauses, groups, words.
foreach puntuation char:
report count
That looks like we could create maybe 4 functions using the natural grouping
above. This might help us build a module that could be reused either whole
or in part.
############################# # Module: grammar # Created: A.J. Gauld, 2000,8,12 # # Function: # counts paragraphs, lines, sentences, 'clauses', char groups, # words and punctuation for a prose like text file. It assumes # that sentences end with [.!?] and paragraphs have a blank line # between them. A 'clause' is simply a segment of sentence # separated by punctuation(braindead but maybe someday we'll # do better!) # # Usage: Basic usage takes a filename parameter and outputs all # stats. Its really intended that a second module use the # functions provided to produce more useful commands. ############################# import string, sys ############################ # initialise global variables para_count = 1 # We will assume at least 1 paragraph! line_count, sentence_count, clause_count, word_count = 0,0,0,0 groups = [] punctuation_counts = {} alphas = string.letters + string.digits stop_tokens = ['.','?','!'] punctuation_chars = ['&','(',')','-',';',':',','] + stop_tokens for c in punctuation_chars: punctuation_counts[c] = 0 format = """%s contains: %d paragraphs, %d lines and %d sentences. These in turn contain %d clauses and a total of %d words.""" ############################ # Now define the functions that do the work def getCharGroups(infile): pass def getPunctuation(wordList): pass def reportStats(): print format % (sys.argv[1],para_count, line_count, sentence_count, clause_count, word_count) def Analyze(infile): getCharGroups(infile) getPunctuation(groups) reportStats() # Make it run if called from the command line (in which # case the 'magic' __name__ variable gets set to '__main__' if __name__ == "__main__": if len(sys.argv) != 2: print "Usage: python grammar.py <filename>" sys.exit() else: Document = open(sys.argv[1],"r") Analyze(Document) Document.close()Rather than trying to show the whole thing in one long listing I'll discuss this skeleton then we will look at each of the 3 significant functions in turn. To make the program work you will need to paste it all together at the end however.
First thing to notice is the commenting at the top. This is common practice to let readers of the file get an idea of what it contains and how it should be used. The version information(Author and date) is useful too if comparing results with someone else who may be using a more or less recent version.
The final section is a feature of Python that calls any module loaded at the command line "__main__" . We can test the special, built-in __name__ variable and if its main we know the module is not just being imported but run and so we execute the trigger code inside the if.
This trigger code includes a user friendly hint about how the program should be run if no filename is provided, or indeed if too many filenames are provided.
Finally notice that the Analyze() function simply calls the other functions in the right order. Again this is quite common practice to allow a user to choose to either use all of the functionality in a straightforward manner (through Analyze()) or to call the low level primitive functions directly.
foreach line in file:
increment line count
if line empty:
increment paragraph count
split line into character groups
We can implement this in Python with very little extra effort:
# use global counter variables and list of char groups def getCharGroups(infile): global para_count, line_count, groups try: for line in infile.readlines(): line_count = line_count + 1 if len(line) == 1: # only newline => para break para_count = para_count + 1 else: groups = groups + string.split(line) except: print "Failed to read file ", sys.argv[1] sys.exit()Note 1: We have to use the global keyword here to declare the variables which are created outside of the function. If we didn't when we assign to them Python will create new variables of the same name local to this function. Changing these local variables will have no effect on the module level (or global) values
Note 2: We have used a try/except clause here to trap any errors, report the failure and exit the program.
This takes a little bit more effort and uses a couple of new features of Python.
The pseudo code looked like:
foreach character group:
increment group count
extract punctuation chars into a dictionary - {char:count}
if no chars left:
delete group
else: increment word count
My first attempt looked like this:
def getPunctuation(wordList):
global punctuation_counts
for item in wordList:
while item and (item[-1] not in alphas):
p = item[-1]
item = item[:-1]
if p in punctuation_counts.keys():
punctuation_counts[p] = punctuation_counts[p] + 1
else: punctuation_counts[p] = 1
Notice that this does not include the final if/else clause of
the pseudo-code version. I left it off for simplicity and because I felt
that in practice very few words containing only punctuation characters
would be found. We will however add it to the final version of the code.
Note 1: We have parameterised the wordList so that users of the module can supply their own list rather than being forced to work from a file.
Note 2: We assigned item[:-1] to item. This is known as slicing in Python and the colon simply says treat the index as a range. We could for example have specified item[3:6] to extract item[3], item[4] and item[5] into a list.
The default range is the start or end of the list depending on which side of the colon is blank. Thus item[3:] would signify all members of item from item[3] to the end. Again this is a very useful Python feature. The original sequence item is lost (and duly garbage collected) and the newly created sequence assigned to item
Note 3: We use a negative index to extract the last character from item. This is a very useful Python feature. Also we loop in case there are multiple punctuation characters at the end of a group.
In testing this it became obvious that we need to do the same at the front of a group too, since although closing brackets are detected opening ones aren't! To overcome this problem I will create a new function trim() that will remove punctuation from front and back of a single char group:
#########################################################
# Note trim uses recursion where the terminating condition
# is either 0 or -1. An "InvalidEnd" error is raised for
# anything other than -1, 0 or 2.
##########################################################
def trim(item,end = 2):
""" remove non alphas from left(0), right(-1) or both ends of item"""
if end not in [0,-1,2]:
raise "InvalidEnd"
if end == 2:
trim(item, 0)
trim(item, -1)
else:
while (len(item) > 0) and (item[end] not in alphas):
ch = item[end]
if ch in punctuation_counts.keys():
punctuation_counts[ch] = punctuation_counts[ch] + 1
if end == 0: item = item[1:]
if end == -1: item = item[:-1]
return item
Notice how the use of recursion combined with defaulted a parameter enables
us to define a single trim function which by default trims both ends, but
by passing in an end value can be made to operate on only one end. The
end values are chosen to reflect Python's indexing system: 0 for the left
end and -1 for the right. I originally wrote two trim functions, one for
each end but the amount of similarity made me realize that I could combine
them using a parameter. Something else to note is that trim makes
multiple copies of the string, one for each character it removes
(this is a side-effect of the slice operation). Potentially that
could be quite slow(in computer terms) if we removed a lot of
characters, however in practice we are likely to only remove
a few, so it doesn't really matter in this case.
And getPuntuation becomes the nearly trivial:
def getPunctuation(wordList):
for item in wordList:
trim(item)
# Now delete any empty 'words'
for i in range(len(wordList)):
if len(wordList[i]) == 0:
del(wordList[i])
Note 1: This now includes the deletion of blank words.
Note 2: In the interests of reusability we might have been better to break trim down into smaller chunks yet. This would have enabled us to create a function for removing a single punctuation character from either front or back of a word and returning the character removed. Then another function would call that one repeatedly to get the end result. However since our module is really about producing statistics from text rather than general text processing that should properly involve creating a separate module which we could then import. But since it would only have the one function that doesn't seem too useful either. So I'll leave it as is!
The only thing remaining is to improve the reporting to include the punctuation characters and the counts. Replace the existing reportStats() function with this:
def reportStats():
global sentence_count, clause_count
for p in stop_tokens:
sentence_count = sentence_count + punctuation_counts[p]
for c in punctuation_counts.keys():
clause_count = clause_count + punctuation_counts[c]
print format % (sys.argv[1],
para_count, line_count, sentence_count,
clause_count, len(groups))
print "The following punctuation characters were used:"
for p in punctuation_counts.keys():
print "\t%s\t:\t%3d" % (p, punctuation_counts[p])
If you have carefully stitched all the above functions in place you should
now be able to type:
C:> python grammar.py myfile.txtand get a report on the stats for your file myfile.txt (or whatever it's really called). How useful this is to you is debateable but hopefully reading through the evolution of the code has helped you get some idea of how to create your own programs. The main thing is to try things out. Oh yes, and test them carefully. If you do that with this program you can quickly find ways to trick it into giving phony answers - for example by inserting elipses(...) into the file you get too high a sentence count. You could add special code to detect these kinds of situations, or you could decide its good enough for casual use. Its up to you.
There's no shame in trying several approaches, often you learn valuable lessons in the process.
To conclude our course we will rework the grammar module to use OO techniques. In the process you will see how an OO approach results in modules which are even more flexible for the user and more extensible too.
One of the biggest problems for the user of our module is the reliance on global variables. This means that it can only analyze one document at a time, any attempt to handle more than that will result in the global values being over-written.
By moving these globals into a class we can then create multiple instances of the class (one per file) and each instance gets its own set of variables. Further, by making the methods sufficiently granular we can create an architecture whereby it is easy for the creator of a new type of document object to modify the search criteria to cater for the rules of the new type. (eg. by rejecting all HTML tags from the word list).
Our first attempt at this is:
#! /usr/local/bin/python ################################ # Module: document.py # Author: A.J. Gauld # Date: 2000/08/12 # Version: 2.0 ################################ # This module provides a Document class which # can be subclassed for different categories of # Document(text, HTML, Latex etc). Text and HTML are # provided as samples. # # Primary services available include # - getCharGroups(), # - getWords(), # - reportStats(). ################################ import sys,string class Document: def __init__(self, filename): self.filename = filename self.para_count = 1 self.line_count, self.sentence_count, self.clause_count, self.word_count = 0,0,0,0 self.alphas = string.letters + string.digits self.stop_tokens = ['.','?','!'] self.punctuation_chars = ['&','(',')','-',';',':',','] + self.stop_tokens self.lines = [] self.groups = [] self.punctuation_counts = {} for c in self.punctuation_chars + self.stop_tokens: self.punctuation_counts[c] = 0 self.format = """%s contains: %d paragraphs, %d lines and %d sentences. These in turn contain %d clauses and a total of %d words.""" def getLines(self): try: self.infile = open(self.filename,"r") self.lines = self.infile.readlines() self.infile.close() except: print "Failed to read file ",self.filename sys.exit() def getCharGroups(self, lines): for line in lines: line = line[:-1] # lose the '\n' at the end self.line_count = self.line_count + 1 if len(line) == 0: # empty => para break self.para_count = self.para_count + 1 else: self.groups = self.groups + string.split(line) def getWords(self): pass def reportStats(self, paras=1, lines=1, sentences=1, words=1, punc=1): pass def Analyze(self): self.getLines() self.getCharGroups(self.lines) self.getWords() self.reportStats() class TextDocument(Document): pass class HTMLDocument(Document): pass if __name__ == "__main__": if len(sys.argv) != 2: print "Usage: python document.py <filename>" sys.exit() else: D = Document(sys.argv[1]) D.Analyze()
Now to implement the class we need to define the getWords method. We could simply copy what we did in the previous version and create a trim method, however we want the OO version to be easily extendible so instead we'll break getWords down into a series of steps. Then in subclasses we only need to override the substeps and not the whole getWords method. This should allow a much wider scope for dealing with different types of document.
Specifically we will add methods to reject groups which we recognise as invalid, trim unwanted characters from the front and from the back. Thus we add 3 methods to Document and implement getWords in terms of these methods.
class Document:
# .... as above
def getWords(self):
for w in self.groups:
self.ltrim(w)
self.rtrim(w)
self.removeExceptions()
def removeExceptions(self):
pass
def ltrim(self,word):
pass
def rtrim(self,word):
pass
Notice however that we define the bodies with the single command pass, which does absolutely nothing. Instead we will define how these methods operate for each concrete document type.
A text document looks like:
class TextDocument(Document):
def ltrim(self,word):
while (len(word) > 0) and (word[0] not in self.alphas):
ch = word[0]
if ch in self.c_punctuation.keys():
self.c_punctuation[ch] = self.c_punctuation[ch] + 1
word = word[1:]
return word
def rtrim(self,word):
while (len(word) > 0) and (word[-1] not in self.alphas):
ch = word[-1]
if ch in self.c_punctuation.keys():
self.c_punctuation[ch] = self.c_punctuation[ch] + 1
word = word[:-1]
return word
def removeExceptions(self):
self.groups = filter(lambda g: len(g) > 0, self.groups)
The trim functions are virtually identical to our grammar.py module's trim function, but split into two. The removeExceptions function has been defined to remove blank words. Note the use of the Functional Programming filter function.
Thus HTMLDocument looks like:
class HTMLDocument(TextDocument):
def removeExceptions(self):
""" use regular expressions to remove all <.+?> """
import re
tag = re.compile("<.+?>")# use non greedy re
L = 0
while L < len(self.lines):
if len(self.lines[L]) > 1: # if its not blank
self.lines[L] = tag.sub('', self.lines[L])
if len(self.lines[L]) == 1:
del(self.lines[L])
else: L = L+1
else: L = L+1
def getWords(self):
self.removeExceptions()
for i in range(len(self.groups)):
w = self.groups[i]
w = self.ltrim(w)
self.groups[i] = self.rtrim(w)
TextDocument.removeExceptions(self)# now strip empty words
Note 1: The only thing to note here is the call to
self.removeExceptions before trimming and then calling
TextDocument.removeExceptions. If we had relied on the
inherited getWords it would have called our
removeExceptions after trimming which we don't want.
Finally we need to modify Analyze to call generateStats() and the main sequence to specifically call printStats() after Analyze. With these changes in place the existing code will carry on working as before, at least as far as the command line user is concerned. Other programmers will have to make slight changes to their code to printStats() after using Analyze - not too onerous a change.
The revised code segments look like this:
def generateStats(self):
self.word_count = len(self.groups)
for c in self.stop_tokens:
self.sentence_count = self.sentence_count + self.punctuation_counts[c]
for c in self.punctuation_counts.keys():
self.clause_count = self.clause_count + self.punctuation_counts[c]
def printStats(self):
print self.format % (self.filename, self.para_count,
self.line_count, self.sentence_count,
self.clause_count, self.word_count)
print "The following punctuation characters were used:"
for i in self.punctuation_counts.keys():
print "\t%s\t:\t%4d" % (i,self.punctuation_counts[i])
and:
if __name__ == "__main__":
if len(sys.argv) != 2:
print "Usage: python document.py <filename>"
sys.exit()
else:
try:
D = HTMLDocument(sys.argv[1])
D.Analyze()
D.printStats()
except:
print "Error analyzing file: %s" % sys.argv[1]
Now we are ready to create a GUI wrapper around our document classes.
The first step is to try to visualise how it will look. We need to specify a filename, so it will require an Edit or Entry control. We also need to specify whether we want textual or HTML analysis, this type of 'one from many' choice is usually represented by a set of Radiobutton controls. These controls should be grouped together to show that they are related.
The next requirement is for some kind of display of the results. We could opt for multiple Label controls one per counter. Instead I will use a simple text control into which we can insert strings, this is closer to the spirit of the commandline output, but ultimately the choice is a matter of preference by the designer.
Finally we need a means of initiating the analysis and quitting the application. Since we will be using a text control to display results it might be useful to have a means of resetting the display too. These command options can all be represented by Button controls.
Sketching these ideas as a GUI gives us something like:
+-------------------------+-----------+ | FILENAME | O TEXT | | | O HTML | +-------------------------+-----------+ | | | | | | | | | | +-------------------------------------+ | | | ANALYZE RESET QUIT | | | +-------------------------------------+
from Tkinter import * import document ################### CLASS DEFINITIONS ###################### class GrammarApp(Frame): def __init__(self, parent=0): Frame.__init__(self,parent) self.type = 2 # create variable with default value self.master.title('Grammar counter') self.buildUI()
Here we have imported the Tkinter and document modules. For the former we have made all of the Tkinter names visible within our current module whereas with the latter we will need to prefix the names with 'document.'
We have also defined an __init__ method which calls the Frame.__init__ superclass method to ensure that Tkinter is set up properly internally. We then create an attribute which will store the document type value and finally call the buildUI method which creates all the widgets for us.
def buildUI(self):
# Now the file information: File name and type
fFile = Frame(self)
Label(fFile, text="Filename: ").pack(side="left")
self.eName = Entry(fFile)
self.eName.insert(INSERT,"test.htm")
self.eName.pack(side=LEFT, padx=5)
# to keep the radio buttons lined up with the
# name we need another frame
fType = Frame(fFile, borderwidth=1, relief=SUNKEN)
self.rText = Radiobutton(fType, text="TEXT",
variable = self.type, value=2,
command=self.doText)
self.rText.pack(side=TOP, anchor=W)
self.rHTML = Radiobutton(fType, text="HTML",
variable=self.type, value=1,
command=self.doHTML)
self.rHTML.pack(side=TOP, anchor=W)
# make TEXT the default selection
self.rText.select()
fType.pack(side=RIGHT, padx=3)
fFile.pack(side=TOP, fill=X)
# the text box holds the output, pad it to give a border
# and make the parent the application frame (ie. self)
self.txtBox = Text(self, width=60, height=10)
self.txtBox.pack(side=TOP, padx=3, pady=3)
# finally put some command buttons on to do the real work
fButts = Frame(self)
self.bAnal = Button(fButts, text="Analyze",
command=self.AnalyzeEvent)
self.bAnal.pack(side=LEFT, anchor=W, padx=50, pady=2)
self.bReset = Button(fButts, text="Reset",
command=self.doReset)
self.bReset.pack(side=LEFT, padx=10)
self.bQuit = Button(fButts, text="Quit",
command=self.doQuitEvent)
self.bQuit.pack(side=RIGHT, anchor=E, padx=50, pady=2)
fButts.pack(side=BOTTOM, fill=X)
self.pack()
I'm not going to explain all of that, instead I recommend you take a look at the Tkinter tutorial found on the Python web site. This is an excellent introduction and reference to Tkinter. The general principle is that you create widgets from their corresponding classes, providing options as named parameters, then the widget is packed into its containing frame.
The other key points to note are the use of subsidiary Frame widgets to hold the Radiobuttons and Command buttons. The Radiobuttons also take a pair of options called variable & value, the former links the Radiobuttons together by specifying the same external variable (self.type) and the latter gives a unique value for each Radiobutton. Also notice the command=xxx options passed to the button controls. These are the methods that will be called by Tkinter when the button is pressed. The code for these comes next:
################# EVENT HANDLING METHODS #################### # time to die... def doQuitEvent(self): import sys sys.exit() # restore default settings def doReset(self): self.txtBox.delete(1.0, END) self.rText.select() # set radio values def doText(self): self.type = 2 def doHTML(self): self.type = 1
These methods are all fairly trivial and hopefully by now are self explanatory. The final event handler is the one which does the analysis:
# Create appropriate document type and analyze it.
# then display the results in the form
def AnalyzeEvent(self):
filename = self.eName.get()
if filename == "":
self.txtBox.insert(END,"\nNo filename provided!\n")
return
if self.type == 2:
doc = document.TextDocument(filename)
else:
doc = document.HTMLDocument(filename)
self.txtBox.insert(END, "\nAnalyzing...\n")
doc.Analyze()
str = doc.format % (doc.filename,
doc.para_count, doc.line_count,
doc.sentence_count, doc.clause_count, doc.word_count)
self.txtBox.insert(END, str)
Again you should be able to read this and see what it does. The key points are that:
All that's needed now is to create an instance of the Application
object and set the event loop running, we do this here:
myApp = GrammarApp() myApp.mainloop()
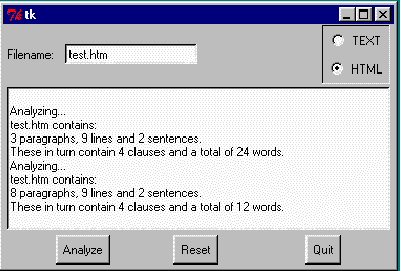
Lets take a look at the final result as seen under MS Windows, displaying the results of analyzing a test HTML file, first in Text mode then in HTML mode:
That's it. You can go on to make the HTML processing more sophisticated if you want to. You can create new modules for new document types. You can try swapping the text box for multiple labels packed into a frame. But for our purposes we're done. The next section offers some ideas of where to go next depending on your programming aspirations. The main thing is to enjoy it and allways remember: the computer is dumb!
If you have any questions or feedback on this page send me mail at: