For this case study we are going to expand on the word counting program we developed earlier. We are going to create a program which mimics the Unix wc program in that it outputs the number of lines, words and characters in a file. We will go further than that however and also output the number of sentences, clauses and paragraphs. We will follow the development of this program stage by stage, gradually increasing its capability, then moving it into a module to make it reusable, turning it into an OO implementation for maximum extendability and finally wrapping it in a GUI for ease of use.
Although we will be using Python throughout it would be possible to build JavaScript or VBScript versions of the program with only a little adaptation.
Additional features that could be implemented but will be left as exercises for the reader are to
(Average words per sentence) + (Percentage of words more than 5 letters) * 0.4and indicates the complexity of the text.
Let's revisit the previous word counter:
import string
def numwords(s):
lst = string.split(s)
return len(lst)
with open("menu.txt","r") as inp:
total = 0
# accumulate totals for each line
for line in inp.readlines():
total += numwords(line)
print( "File had %d words" % total )
We need to add a line and character count. The line count is easy since we loop over each line we just need a variable to increment on each iteration of the loop. The character count is only marginally harder since we can iterate over the list of words adding their lengths in yet another variable.
We also need to make the program more general purpose by reading the name of the file from the command line or, if not provided, prompting the user for the name. (An alternative strategy would be to read from standard input, which is what the real wc does.)
So the final wc.py looks like:
import sys, string # Get the file name either from the command-line or the user if len(sys.argv) != 2: name = input("Enter the file name: ") else: name = sys.argv[1] # initialize counters to zero; which also creates variables words, lines, chars = 0, 0, 0 with open(name,"r") as inp: for line in inp: lines += 1 # Break into a list of words and count them lst = line.split() words += len(lst) chars += len(line) # Use original line which includes spaces etc. print( "%s has %d lines, %d words and %d characters" % (name, lines, words, chars) )
If you are familiar with the Unix wc command you know that you can pass it a wild-carded filename to get stats for all matching files as well as a grand total. This program only caters for a single filename. If you want to extend it to cater for wild cards take a look at the glob module and build a list of names then simply iterate over the file list. You'll need temporary counters for each file then cumulative counters for the grand totals. Or you could use a dictionary instead...
When I started to think about how we could extend this to count sentences and words rather than 'character groups' as above, my initial idea was to first loop through the file extracting the lines into a list then loop through each line extracting the words into another list. Finally to process each 'word' to remove extraneous characters.
Thinking about it a little further it becomes evident that if we simply collect the lines we can analyze the punctuation characters to count sentences, clauses etc. (by defining what we consider a sentence/clause in terms of punctuation items). Let's try sketching that in pseudo-code:
foreach line in file:
increment line count
if line empty:
increment paragraph count
count the clause terminators
count the sentence terminators
report paras, lines, sentences, clauses, groups, words.
We will be using regular expressions in the solution here, it may be worth going back and reviewing that topic if you aren't sure how they work. Now lets try turning our pseudo code into real code:
import re,sys # Use Regular expressions to find the tokens sentenceStops = ".?!" clauseStops = sentenceStops + ",;:\-" # escape '-' to avoid range effect sentenceRE = re.compile("[%s]" % sentenceStops) clauseRE = re.compile("[%s]" % clauseStops) # Get file name from commandline or user if len(sys.argv) != 2: name = input("Enter the file name: ") else: name = sys.argv[1] # Now initialize counters lines, words, chars = 0, 0, 0 sentences,clauses = 0, 0 paras = 1 # assume always at least 1 para # process file with open(name,"r") as inp: for line in inp: lines += 1 if line.strip() == "": # empty line paras += 1 words += len(line.split()) chars += len(line.strip()) sentences += len(sentenceRE.findall(line)) clauses += len(clauseRE.findall(line)) # Display results output = ''' The file %s contains: %d\t characters %d\t words %d\t lines in %d\t paragraphs with %d\t sentences and %d\t clauses. ''' % (name, chars, words, lines, paras, sentences, clauses) print( output )
There are several points to note about this code:
As the case study progresses we will address the second point about re-usability and also start to look at the issues around parsing text in a little more depth, although even by the end we will not have produced a perfect text parser. That is a task that takes us well beyond the sort of programs a beginner might be expected to write.
To make the code we have written into a module there are a few basic design principles that we need to follow. First we need to put the bulk of the code into functions so that users of the module can access them. Secondly we need to move the start code (the bit that gets the file name) into a separate piece of code that won't be executed when the module is imported. Finally, we will leave the global definitions as module level variables so that users can change their value if they want to.
Let's tackle these items one by one. First move the main processing block into a function, we'll call it analyze(). We'll pass a file object into the function as a parameter and the function will return the list of counter values in a tuple.
It looks like this:
############################# # Module: grammar # Created: A.J. Gauld, 2010/12/02 # Modified: A.J. Gauld, 2018/01/12 # # Function: ''' Provides facilities to count words, lines, characters, paragraphs, sentences and 'clauses' in text files. It assumes that sentences end with [.!?] and paragraphs have a blank line between them. A 'clause' is simply a segment of sentence separated by punctuation. The sentence and clause searches are regular expression based and the user can change the regex used. Can also be run as a program.''' ############################# import re, sys # initialize global variables paras = 1 # We will assume at least 1 paragraph! lines, sentences, clauses, words, chars = 0,0,0,0,0 sentenceMarks = '.?!' clauseMarks = '&();:,/\-' + sentenceMarks sentenceRE = None # set via a function call clauseRE = None format = ''' The file %s contains: %d\t characters %d\t words %d\t lines in %d\t paragraphs with %d\t sentences and %d\t clauses. ''' ############################ # Now define the functions that do the work # setCounterREs allows us to recompile the regex if we change # the token lists def setCounterREs(): "compiles global regexs from global punctuation sets" global sentenceRE, clauseRE sentenceRE = re.compile('[%s]' % sentenceMarks) clauseRE = re.compile('[%s]' % clauseMarks) # reset counters gets called by analyze() def resetCounters(): " reset global counter variables to initial values " chars, words, lines, sentences, clauses = 0,0,0,0,0 paras = 1 # reportStats is intended for the driver # code, it offers a simple text report def reportStats(theFile): " prints out results from global results " print( format % (theFile.name, chars, words, lines, paras, sentences, clauses) ) # analyze() is the key function which processes the file def analyze(theFile): ''' analyze(aFile) -> None Analyzes the input file object putting results in global variables ''' global chars,words,lines,paras,sentences,clauses # check if REs already compiled if not (sentenceRE and clauseRE): setCounterREs() resetCounters() for line in theFile: lines += 1 if line.strip() == "": # empty line paras += 1 words += len(line.split()) chars += len(line.strip()) sentences += len(sentenceRE.findall(line)) clauses += len(clauseRE.findall(line)) # Make it run if called from the command line (in which # case the 'magic' __name__ variable gets set to '__main__' if __name__ == "__main__": if len(sys.argv) != 2: print( "Usage: python grammar.py <filename>" ) sys.exit() else: with open(sys.argv[1],"r") as aFile: analyze(aFile) reportStats(aFile)
First thing to notice is the commenting at the top. This is common practice to let readers of the file get an idea of what it contains and how it should be used. The version information (Author and date) is useful too if comparing results with someone else who may be using a more or less recent version. Notice that the description of the module is a string which is not allocated to a variable. Recall that this creates a documentation string in Python, which can be displayed using the help function. We also have documentation strings on each of the individual function definitions. I won't be adding as much commentary in the other examples (although I will demonstrate a few other styles of comment/documentation)) because the main text describes what's going on. This example shows the sort of thing you could provide.
The final section is a feature of Python that calls any module loaded at the command line "__main__". We can test the special, built-in __name__ variable and, if it's main, we know that the module is not just being imported, but run, and so we execute the driver code inside the if block.
This driver code includes a user friendly hint about how the program should be run if no filename is provided, or indeed if too many filenames are provided, it could instead - or in addition - ask the user for a filename using input().
Notice that the analyze() function uses the initialization functions to make sure the counters and regular expressions are all set up properly before it starts. This caters for the possibility of a user calling analyze several times, possibly after changing the regular expressions used to count clauses and sentences.
Finally note the use of global to ensure that the module level variables get set by the functions, without global we would create local variables and have no effect on the module level ones.
Having created a module we can use it as a program at the OS prompt as before by typing:
C:\> python grammar.py spam.txt
However, provided we saved the module in a location where Python can find it, we can also import the module into another program or at the Python prompt. Let's try some experiments based on a test file called spam.txt which we can create looking like this:
This is a file called spam. It has 3 lines, 2 sentences and, hopefully, 5 clauses.
Now, let's fire up Python and play a little:
>>> import grammar
>>> grammar.setCounterREs()
>>> txtFile = open("spam.txt")
>>> grammar.analyze(txtFile)
>>> grammar.reportStats(txtFile)
The file spam.txt contains:
80 characters
16 words
3 lines in
1 paragraphs with
2 sentences and
5 clauses.
>>> txtFile.close()
>>> txtFile = open('spam.txt')
>>> grammar.resetCounters()
>>> # redefine sentences as ending in vowels!
>>> grammar.sentenceMarks = 'aeiou'
>>> grammar.setCounterREs()
>>> grammar.analyze(txtFile)
>>> print( grammar.sentences )
21
>>> txtFile.close()
Note:When using the interactive prompt it's more convenient to use the traditional open/close on the file than to use with, because with would delay execution until you had typed all of the file operations that would be inside the with block. Using open explicitly you can execute each command in isolation.
As you can see, redefining the sentence tokens changed the sentence count radically. Of course the new definition of a sentence is pretty bizarre but it shows that our module is usable and moderately customizable too. Notice also that we were able to print the sentence count directly, we don't need to use the provided reportStats() function. This demonstrates the value of an important design principle, namely separation of data and presentation. By keeping the display of data separate from the calculation of the data we make our module much more flexible for our users.
To conclude our project we will rework the grammar module to use OO techniques and then add a simple GUI front end. In the process you will see how an OO approach results in modules which are even more flexible for the user and more extensible too.
One of the biggest problems for the user of our module is the reliance on global variables. This means that it can only analyze one file at a time, any attempt to handle more than that will result in the global values being over-written.
By moving these globals into a class we can then create multiple instances of the class (one per file) and each instance gets its own set of variables. Further, by making the methods sufficiently granular we can create an architecture whereby it is easy for the creator of a new type of document object to modify the search criteria to cater for the rules of the new type. (eg. by rejecting all HTML tags from the word list we could process HTML files as well as plain ASCII text).
Our first attempt at this creates a Document class to represent the file we are processing:
#! /usr/local/bin/python
################################
# Module: document.py
# Author: A.J. Gauld
# Date: 2010/12/10
# Version: 3.1
################################
'''
Provides 2 classes for parsing text/files.
A Generic Document class for plain ASCII text,
and an HTMLDocument for HTML files.
Primary services available include
- analyze(),
- reportStats().
'''
import sys,re
class Document:
sentenceMarks = '?!.'
clauseMarks = '&()/\-;:,' + sentenceMarks
def __init__(self, filename):
self.filename = filename
self.setREs()
self.resetCounters()
def resetCounters(self):
self.paras = 1
self.lines = self.getLines()
self.sentences, self.clauses, self.words, self.chars = 0,0,0,0
def setREs(self):
self.sentenceRE = re.compile('[%s]' % Document.sentenceMarks)
self.clauseRE = re.compile('[%s]' % Document.clauseMarks)
def getLines(self):
with open(self.filename)as infile:
lines = infile.readlines()
return lines
def analyze(self):
self.resetCounters()
for line in self.lines:
self.sentences += len(self.sentenceRE.findall(line))
self.clauses += len(self.clauseRE.findall(line))
self.words += len(line.split())
self.chars += len(line.strip())
if line.strip() == "":
self.paras += 1
def formatResults(self):
format = '''
The file %s contains:
%d\t characters
%d\t words
%d\t lines in
%d\t paragraphs with
%d\t sentences and
%d\t clauses.
'''
return format % (self.filename, self.chars,
self.words, len(self.lines),
self.paras, self.sentences, self.clauses)
class TextDocument(Document):
pass
class HTMLDocument(Document):
pass
if __name__ == "__main__":
if len(sys.argv) == 2:
doc = Document(sys.argv[1])
doc.analyze()
print( doc.formatResults() )
else:
print( "Usage: python document3.py <file>" )
print( "Failed to analyze file" )
There are several points to notice here. First is the use of class variables at the beginning of the class definition to store the sentence and clause markers. Class variables are shared by all the instances of the class so they are a good place to store common information. They can be accessed by using the class name, as I've done here, or by using the usual self. I prefer to use the class name because it highlights the fact that they are class variables.
Even though we now store the variables inside the class, resetCounters() is still needed for flexibility when we come to deal with other document types. It's quite likely that we will use a different set of counters when analyzing HTML files - maybe the number of tags for example. By pairing up the resetCounters() and formatResults() methods and providing a new analyze() method we can pretty much deal with any kind of document.
The other methods are more stable, reading the lines of a file is pretty standard regardless of file type and setting the two regular expressions is a convenience feature for experimenting, if we don't need to, we won't.
As it stands we now have functionality identical to our module version but expressed as a class. But now to really utilize OOP style we need to de-construct some of our class so that the base level or abstract Document only contains the bits that are truly generic. The Text handling bits will move into the more specific, or concrete TextDocument class. This process is known as refactoring in professional programming circles. We'll see how to do that next.
We are all familiar with plain text documents, but it's worth stopping to consider exactly what we mean by a text document as compared to a more generic concept of a document. Text documents consist of characters arranged in lines which contain groups of letters arranged as words separated by spaces and other punctuation marks. Groups of lines form paragraphs which are separated by blank lines (other definitions are possible of course, but these are the ones I will use.) A vanilla document is a file comprising lines of characters but we know very little about the formatting of those characters within the lines. Thus, our basic Document class should really only be able to open a file, read the contents into a list of lines and perhaps return counts of the number of characters and the number of lines. It will provide empty hook methods for subclasses of document to implement. (Note: While ASCII text is one of the oldest and arguably the simplest text representation, there are many other alphabets and, in particular, the introduction of Unicode has added a whole layer of complexity to the subject.
On the basis of what we just described a Document class will look like:
############################# # Module: document # Created: A.J. Gauld, 2010/12/15 # Version 3 # Function: ''' Provides abstract Document class to count lines, characters and provide hook methods for subclasses to use to process more specific document types''' ############################# import sys,re class Document: def __init__(self,filename): self.filename = filename self.lines = self.getLines() self.chars = sum( [len(L) for L in self.lines] ) self._initSeparators() def getLines(self): f = open(self.filename,'r') lines = f.readlines() f.close() return lines # list of hook methods to be overridden def formatResults(self): return "%s contains $d lines and %d characters" % (len(self.lines), self.chars) def _initSeparators(self): pass def analyze(self): pass
Note that the _initSeparators method has an underscore in front of its name. This is a style convention often used by Python programmers to indicate a method that should only be called from inside the class's methods, it is not intended to be accessed by users of the object. Such a method is sometimes called protected or private in other languages.
Also notice that I have used the function sum() to calculate the number of characters. sum(), as the name suggests, returns the total of a list of numbers. In this case the list is the list of lengths of the lines in the file produced by the list comprehension.
Finally note that because this is an abstract class we have not provided a runnable option using if __name__ == etc
Our text document now looks like:
class TextDocument(Document):
def __init__(self,filename):
super().__init__(filename)
self.paras = 1
self.words, self.sentences, self.clauses = 0,0,0
# now override hooks
def formatResults(self):
format = '''
The file %s contains:
%d\t characters
%d\t words
%d\t lines in
%d\t paragraphs with
%d\t sentences and
%d\t clauses.
'''
return format % (self.filename, self.chars,
self.words, len(self.lines),
self.paras, self.sentences, self.clauses)
def _initSeparators(self):
sentenceMarks = "[.!?]"
clauseMarks = "[.!?,&:;-]"
self.sentenceRE = re.compile(sentenceMarks)
self.clauseRE = re.compile(clauseMarks)
def analyze(self):
for line in self.lines:
self.sentences += len(self.sentenceRE.findall(line))
self.clauses += len(self.clauseRE.findall(line))
self.words += len(line.split())
self.chars += len(line.strip())
if line.strip() == "":
self.paras += 1
if __name__ == "__main__":
if len(sys.argv) == 2:
doc = TextDocument(sys.argv[1])
doc.analyze()
print( doc.formatResults() )
else:
print( "Usage: python <document> " )
print( "Failed to analyze file" )
One thing to notice is that this combination of classes achieves exactly the same as our first non-OOP version. Compare the length of this with the original file - building reusable objects is not cheap! Unless you are sure you need to create objects for reuse consider doing a non-OOP version; it will probably be less work! However, if you do think you will extend the design, as we will be doing in a moment then the extra work will repay itself.
The next thing to consider is the physical location of the code. We could have shown two files being created, one per class. This is a common OOP practice and keeps things well organized, but at the expense of a lot of small files and a lot of import statements in your code when you come to use those classes/files.
An alternative scheme, which I prefer, is to treat closely related classes as a group and locate them all in one file, at least enough to create a minimal working program. Thus in our case we have combined our Document and TextDocument classes in a single module. This has the advantage that the working class provides a template for users to read as an example of extending the abstract class. It has the disadvantage that changes to the TextDocument may inadvertently affect the Document class and thus break some other code. There is no clear winner here and even in the Python library there are examples of both styles. Pick one style and stick to it would be my advice.
One very useful source of information on this kind of text file manipulation is the book by David Mertz called "Text Processing in Python" and it is available in paper form as well as being online, here. Note however that this is a fairly advanced book aimed at professional programmers so you may find it tough going initially, but persevere because there are some very powerful lessons contained within it.
The next step in our application development is to extend the capabilities so that we can analyze HTML documents. We will do that by creating a new class. Since an HTML document is really a text document with lots of HTML tags and a header section at the top we only need to remove those extra elements and then we can treat it as text. Thus we will create a new HTMLDocument class derived from TextDocument. We will override the getLines() method that we inherit from Document such that it throws away the header and all the HTML tags.
Thus HTMLDocument looks like:
class HTMLDocument(TextDocument):
def getLines(self):
lines = super().getLines()
lines = self._stripHeader(lines)
lines = self._stripTags(lines)
return lines
def _stripHeader(self,lines):
''' remove all lines up until start of body '''
bodyMark = '<body>'
bodyRE = re.compile(bodyMark,re.IGNORECASE)
while bodyRE.findall(lines[0]) == []:
del lines[0]
return lines
def _stripTags(self,lines):
''' remove anything between < and >, not perfect but ok for now'''
tagMark = '<.+>'
tagRE = re.compile(tagMark)
lines2 = []
for line in lines:
line = tagRE.sub('',line).strip()
if line: lines2.append(line)
return lines2
Note 1: We have used the inherited method within getLines. This is quite common practice when extending an inherited method. Either we do some preliminary processing or, as here, we call the inherited code then do some extra work in the new class. This was also done in the __init__ method of the TextDocument class above.
Note 2: We access the inherited getLines method via super() even though the method is actually defined all the way up in our abstract Document class. TextDocument inherits all of Document's features so, in effect, does have a getLines too. Trust in Python and super to find the right method.
Note 3: The other two methods are notionally private (notice the leading underscore?) and are there to keep the logic separate and also to make extending this class easier in the future, for say, an XHTML, or even XML document class? You might like to try building one of those as an exercise.
Note 4: It is very difficult to accurately strip HTML tags using regular expressions due to the ability to nest tags and because bad authoring often results in unescaped '<' (<) and '>' (>) characters looking like tags when they are not. In addition tags can run across lines and all sorts of other nasties. A much better way to convert HTML files to text is to use an HTML parser such as the one in the standard html.parser module. As an exercise rewrite the HTMLDocument class to use the parser module to generate the text lines. (We describe HTML parsing in the web client topic in the next section.)
To test our HTMLDocument we need to modify the driver code at the bottom of the file to look like this:
if __name__ == "__main__":
if len(sys.argv) == 2:
doc = HTMLDocument(sys.argv[1])
doc.analyze()
print( doc.formatResults() )
else:
print( "Usage: python <document> " )
print( "Failed to analyze file" )
Maybe you are familiar with other filetypes that you could create checking classes for? Examples would inlude PDF, LaTeX, RTF, Postscript, and many others.
To create a GUI we will use Tkinter which we introduced briefly in the Event Driven Programming section and further in the GUI Programming topic. This time the GUI will be slightly more sophisticated and use a few more of the widgets that Tkinter provides.
One thing that will help us create the GUI version is that we took great care to avoid putting any print statements in our classes, the display of output is all done in the driver code. This helps when we come to use a GUI because we can use the same output string and display it in a widget instead of printing it on stdout. The ability to more easily wrap an application in a GUI is a major reason to avoid the use of print statements inside data processing functions or methods.
The first step in building any GUI application is to try to visualize how it will look. We will need to specify a filename, so it will require an Edit or Entry control. We also need to specify whether we want textual or HTML analysis, this type of 'one from many' choice is usually represented by a set of Radiobutton controls. These controls should be grouped together to show that they are related.
The next requirement is for some kind of display of the results. We could opt for multiple Label controls one per counter. Instead I will use a simple text control into which we can insert strings, this is closer to the spirit of the command-line output, but ultimately the choice is a matter of preference by the designer. The advantage of simple text is that the user can scroll back to see previous results, but the down side is that it doesn't look as pretty.
Finally we need a means of initiating the analysis and quitting the application. Since we will be using a text control to display results it might be useful to have a means of resetting the display too. These command options can all be represented by Button controls.
Sketching these ideas as a GUI gives us something like:
+-------------------------+-----------+ | FILENAME | O TEXT | | | O HTML | +-------------------------+-----------+ | | | | | | | | | | +-------------------------------------+ | | | ANALYZE RESET QUIT | | | +-------------------------------------+
In terms of design that looks like 3 full-width frames on top of each other (so we can use a pack layout). The top frame has two frames side by side (again we can use pack for that). The top right frame has two radio buttons arranged vertically - again pack is fine. The bottom frame has three buttons arranged horizontally, and pack can do that too. So we now know what widgets we need and the layout manager for each frame. The only real new feature is the use of the radio buttons, we'll look at that in due course. Let's turn it into code.
import tkinter as tk import document ################### CLASS DEFINITIONS ###################### class GrammarApp(Frame): def __init__(self, parent=0): super().__init__(parent) self.type = 1 # create variable with default value self.master.title('Grammar counter') self.buildUI()
Here we have imported the tkinter and document modules. For the former we have made all of the Tkinter names visible within our current module whereas with the latter we will need to prefix the names with document.
We have also defined our application to be a subclass of Frame and the __init__ method calls the Frame.__init__ superclass method to ensure that Tkinter is set up properly internally. We then create an attribute which will store the document type value and finally call the buildUI method which creates all the widgets for us. We'll look at buildUI() next:
def buildUI(self):
# First the Options frame
# - File name and type
fOpts = tk.Frame(self)
fFile = tk.Frame(fOpts)
tk.Label(fFile, text="Filename: ").pack(side="left")
self.eName = tk.Entry(fFile)
self.eName.insert(tk.INSERT,"test.htm")
self.eName.pack(side='left', padx=5)
fFile.pack(side='left', padx=3)
Now the radio buttons
fType = Frame(fFile, borderwidth=1, relief=tk.SUNKEN)
self.rText = Radiobutton(fType, text="TEXT",
variable = self.type, value=1,
command=self.doText)
self.rText.pack(side=tk.TOP, anchor=tk.W)
self.rHTML = Radiobutton(fType, text="HTML",
variable=self.type, value=2,
command=self.doHTML)
self.rHTML.pack(side=tk.TOP, anchor=tk.W)
# make TEXT the default selection
self.rText.select()
fType.pack(side=tk.RIGHT, padx=3)
fOpts.pack(side=tk.TOP, fill=tk.X)
# the text box holds the output, pad it to give a border
# and make the parent the application frame (ie. self)
self.txtBox = Text(self, width=60, height=10)
self.txtBox.pack(side=tk.TOP, padx=3, pady=3)
# finally put some command buttons on to do the real work
fButts = Frame(self)
self.bAnal = Button(fButts, text="Analyze",
command=self.doAnalyze)
self.bAnal.pack(side=tk.LEFT, anchor=tk.W, padx=50, pady=2)
self.bReset = Button(fButts, text="Reset",
command=self.doReset)
self.bReset.pack(side=tk.LEFT, padx=10)
self.bQuit = Button(fButts, text="Quit",
command=self.quit)
self.bQuit.pack(side=tk.RIGHT, anchor=tk.E, padx=50, pady=2)
fButts.pack(side=tk.BOTTOM, fill=tk.X)
self.pack()
I'm not going to explain all of that. If you've read my GUI topic it should mostly be clear but for more detail I recommend that you take a look at the Tkinter tutorial and reference found on the effbot.org web site. This is an excellent introduction and reference to Tkinter, going beyond the basics that I cover in my topic. The general principle is that you create widgets from their corresponding classes, providing options as named parameters, then the widget is packed into its containing frame. (One nice feature that you might like to try adding is a "browse" button which launches a FileOpen dialog. This could be done using the standard Tkinter dialogs - see the tutorial above for details)
The other key points to note are the use of subsidiary Frame widgets to hold the Radiobuttons and command Buttons. The Radiobuttons also take a pair of options called variable & value, the former links the Radiobuttons together by specifying the same external variable (self.type) and the latter gives a unique value for each Radiobutton. Also notice the command=xxx options passed to the button controls. These are the methods that will be called by Tkinter when the button is pressed. The code for these comes next:
################# EVENT HANDLING METHODS #################### # restore default settings def doReset(self): self.txtBox.delete(1.0, tk.END) self.rText.select() # set radio values def doText(self): self.type = 1 def doHTML(self): self.type = 2
These methods are all fairly trivial and hopefully by now are self explanatory.
The Radiobuttons actually come with a bit of Tkinter magic that allows them to be linked to special types of Python variables such that when the button is clicked it automatically assigns its value to the linked variable. I have not used this technique since it is very Tkinter specific and have instead used the regular event handling mechanism so that everything is familiar to the reader and explicit in its function.
If you are interested in the automated option research IntVar and StringVar in the Tkinter reference. These special variable types can be used with several of the value-setting widgets in Tkinter which are beyond the scope of this tutor.
The final event handler is the one which does the analysis:
# Create appropriate document type and analyze it.
# then display the results in the form
def doAnalyze(self):
filename = self.eName.get()
if filename == "":
self.txtBox.insert(tk.END,"\nNo filename provided!\n")
return
if self.type == 1:
doc = document.TextDocument(filename)
else:
doc = document.HTMLDocument(filename)
self.txtBox.insert(tk.END, "\nAnalyzing...\n")
doc.analyze()
resultStr = doc.formatResults()
self.txtBox.insert(tk.END, resultStr)
Again you should be able to read this and see what it does. The key points are that:
All that's needed now is to create an instance of the
GrammarApp application class and set the event loop
running, we do this here:
if __name__ == "__main__":
myApp = GrammarApp()
myApp.mainloop()
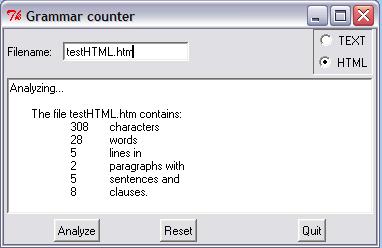
Let's take a look at the final result as seen under MS Windows, displaying the results of analyzing a test HTML file,
That's it. You can go on to make the HTML processing more sophisticated if you want to. You could add a lot more error checking - eg if the file doesn't exist. You can create new modules for new document types. You can try swapping the text box for multiple labels packed into a frame. You could use a drop down list for the document types - especially if you add more types. But for our purposes we're done.
The next section looks at the practical side of Python in real world projects. You'll find the examples are longer and there is a bit less detail in the explanations - by now you should be able to follow along fairly easily. The main thing is to enjoy it and always remember: the computer is dumb!